Module kerod.layers.smca.weight_map
None
None
View Source
import tensorflow as tf
from kerod.utils.documentation import remove_unwanted_doc
__pdoc__ = {}
class DynamicalWeightMaps(tf.keras.layers.Layer):
"""Dynamical spatial weight maps described in
[Fast Convergence of DETR with Spatially Modulated Co-Attention](https://arxiv.org/pdf/2101.07448.pdf).
Each object query first dynamically predicts the center and scale
of its responsible object, which are then used to generate a 2-D Gaussian
like spatial weight map.
Example:
This is an example of spatial weight maps from a 20 x 20 tensor and where we generated
25 random reference points.
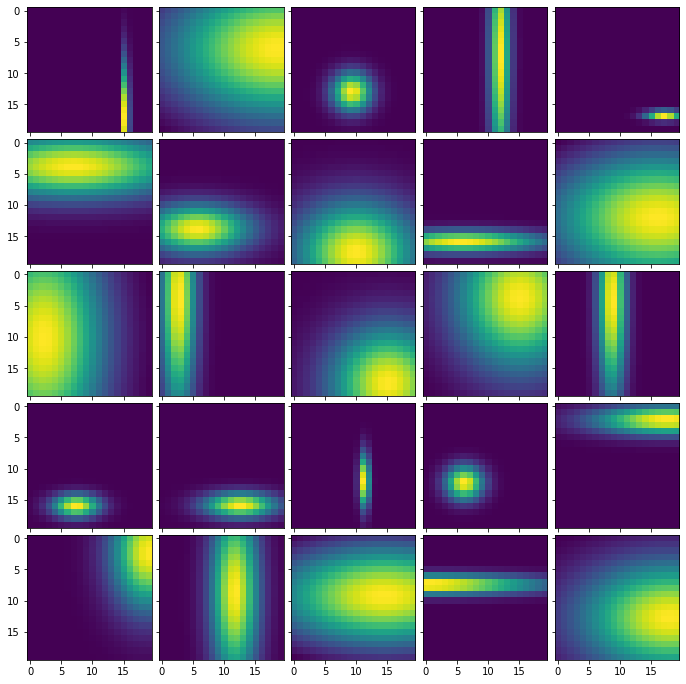
This spatial_weight_map is then flatten to obtain a [25, 400] matrix representing the
the modulated co-attention.

Args:
beta: Modulate the bandwidth of the Gaussian-like distribution.
Call arguments:
height: The targeted height of the feature map
width: The targeted width of the feature map
ref_points: A tensor of shape [batch_size, N, heads, (y, x, h, w)] in [0, 1]
Call returns:
tf.Tensor: The weight_map per reference points
a 4D tensor of float 32 and shape
[batch_size, heads, N, height * width].
"""
def __init__(self, beta=8., **kwargs):
super().__init__(**kwargs)
self._beta = beta
def call(self, height: int, width: int, ref_points: tf.Tensor):
"""
Args:
height: The targeted height of the feature map
width: The targeted width of the feature map
ref_points: A tensor of shape [batch_size, N, heads, (y, x, h, w)] in [0, 1]
Returns:
tf.Tensor: The weight_map per reference points
a 4D tensor of float 32 and shape
[batch_size, heads, N, height * width].
"""
x = tf.cast(tf.linspace(0, 1, width), self.dtype)
y = tf.cast(tf.linspace(0, 1, height), self.dtype)
x, y = tf.meshgrid(x, y) # x and y have shape [height, width]
ref_points = tf.transpose(ref_points, (0, 2, 1, 3))
y_cent, x_cent, h, w = tf.split(ref_points, 4, axis=-1)
# [batch_size, heads, N, 1] => [batch_size,heads, N, 1, 1]
y_cent, x_cent = y_cent[..., tf.newaxis], x_cent[..., tf.newaxis]
h, w = h[..., tf.newaxis], w[..., tf.newaxis]
# [height, width] => [1, 1, 1, height, width]
y, x = y[tf.newaxis, tf.newaxis, tf.newaxis], x[tf.newaxis, tf.newaxis, tf.newaxis]
# [batch_size, heads, N, height, width]
beta = tf.cast(tf.convert_to_tensor(self._beta), self.dtype)
x_term = -(x - x_cent)**2 / (beta * w**2)
y_term = -(y - y_cent)**2 / (beta * h**2)
weight_map = tf.math.exp(x_term + y_term)
batch_size, num_heads = tf.shape(weight_map)[0], tf.shape(weight_map)[1]
return tf.reshape(weight_map, (batch_size, num_heads, -1, height * width))
def get_config(self):
config = super().get_config()
config['beta'] = self._beta
return config
remove_unwanted_doc(DynamicalWeightMaps, __pdoc__)
Classes
DynamicalWeightMaps
class DynamicalWeightMaps(
beta=8.0,
**kwargs
)
Fast Convergence of DETR with Spatially Modulated Co-Attention.
Each object query first dynamically predicts the center and scale of its responsible object, which are then used to generate a 2-D Gaussian like spatial weight map.
Example:
This is an example of spatial weight maps from a 20 x 20 tensor and where we generated 25 random reference points.

This spatial_weight_map is then flatten to obtain a [25, 400] matrix representing the the modulated co-attention.

Args: beta: Modulate the bandwidth of the Gaussian-like distribution.
Call arguments: height: The targeted height of the feature map width: The targeted width of the feature map ref_points: A tensor of shape [batch_size, N, heads, (y, x, h, w)] in [0, 1]
Call returns: tf.Tensor: The weight_map per reference points a 4D tensor of float 32 and shape [batch_size, heads, N, height * width].
Ancestors (in MRO)
- tensorflow.python.keras.engine.base_layer.Layer
- tensorflow.python.module.module.Module
- tensorflow.python.training.tracking.tracking.AutoTrackable
- tensorflow.python.training.tracking.base.Trackable
- tensorflow.python.keras.utils.version_utils.LayerVersionSelector
Methods
call
def call(
self,
height: int,
width: int,
ref_points: tensorflow.python.framework.ops.Tensor
)
Parameters:
| Name | Description |
|---|---|
| height | The targeted height of the feature map |
| width | The targeted width of the feature map |
| ref_points | A tensor of shape [batch_size, N, heads, (y, x, h, w)] in [0, 1] |
Returns:
| Type | Description |
|---|---|
| tf.Tensor | The weight_map per reference points a 4D tensor of float 32 and shape [batch_size, heads, N, height * width]. |
View Source
def call(self, height: int, width: int, ref_points: tf.Tensor):
"""
Args:
height: The targeted height of the feature map
width: The targeted width of the feature map
ref_points: A tensor of shape [batch_size, N, heads, (y, x, h, w)] in [0, 1]
Returns:
tf.Tensor: The weight_map per reference points
a 4D tensor of float 32 and shape
[batch_size, heads, N, height * width].
"""
x = tf.cast(tf.linspace(0, 1, width), self.dtype)
y = tf.cast(tf.linspace(0, 1, height), self.dtype)
x, y = tf.meshgrid(x, y) # x and y have shape [height, width]
ref_points = tf.transpose(ref_points, (0, 2, 1, 3))
y_cent, x_cent, h, w = tf.split(ref_points, 4, axis=-1)
# [batch_size, heads, N, 1] => [batch_size,heads, N, 1, 1]
y_cent, x_cent = y_cent[..., tf.newaxis], x_cent[..., tf.newaxis]
h, w = h[..., tf.newaxis], w[..., tf.newaxis]
# [height, width] => [1, 1, 1, height, width]
y, x = y[tf.newaxis, tf.newaxis, tf.newaxis], x[tf.newaxis, tf.newaxis, tf.newaxis]
# [batch_size, heads, N, height, width]
beta = tf.cast(tf.convert_to_tensor(self._beta), self.dtype)
x_term = -(x - x_cent)**2 / (beta * w**2)
y_term = -(y - y_cent)**2 / (beta * h**2)
weight_map = tf.math.exp(x_term + y_term)
batch_size, num_heads = tf.shape(weight_map)[0], tf.shape(weight_map)[1]
return tf.reshape(weight_map, (batch_size, num_heads, -1, height * width))